一、训练模型
项目地址:https://github.com/THU-MIG/yolov10
下载项目:
1 | git clone https://github.com/THU-MIG/yolov10.git |
按照官方文档安装环境:
1 | conda create -n yolov10 python=3.9 |
准备训练数据:
新建文件zt30.yaml,写入下面文档,这里改成自己的数据集位置,标签信息按照自己的情况进行修改:
1 | # moncake |
训练模型:
1 | yolo detect train data=E:\python-project\yolov10\ultralytics\datasets\zt30.yaml model=yolov10s.pt epochs=500 imgsz=640 device=0 |
这里是训练500次,图像大小640,使用第一个GPU进行训练,按自己的条件进行调整。
训练完成后会在yolov10\runs\detect\train\weights目录下面产生一个best.pt的模型文件,这就是我们训练好的模型;
二、pt转onnx
将yolov10项目下的这两个文件进行修改:
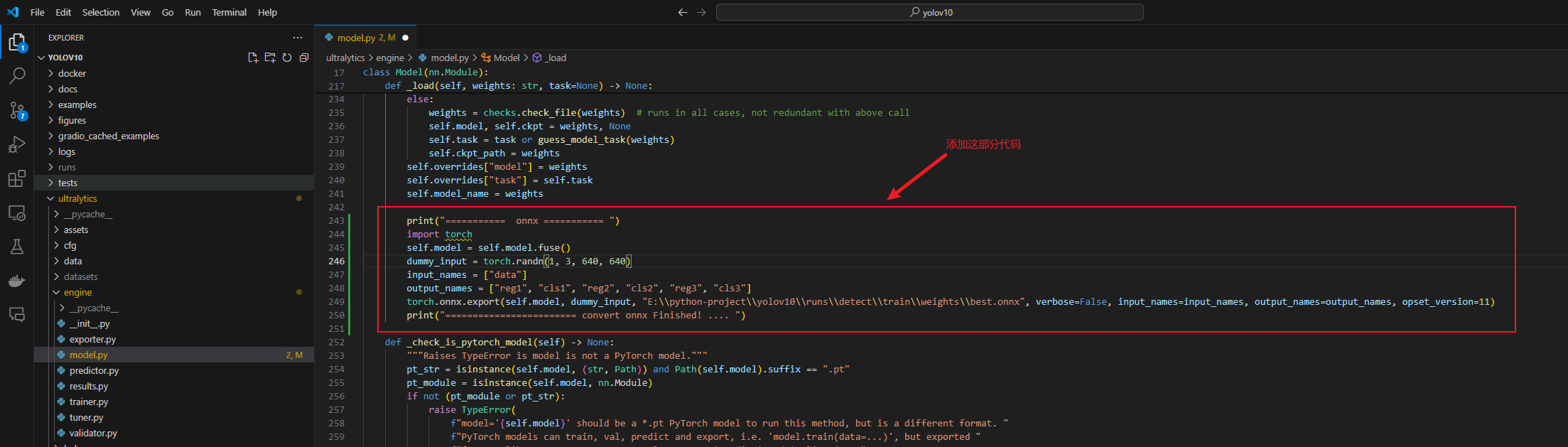
添加这部分代码,其中导出的模型位置和模型图像大小按照自己的情况调整:
1 | print("=========== onnx =========== ") |
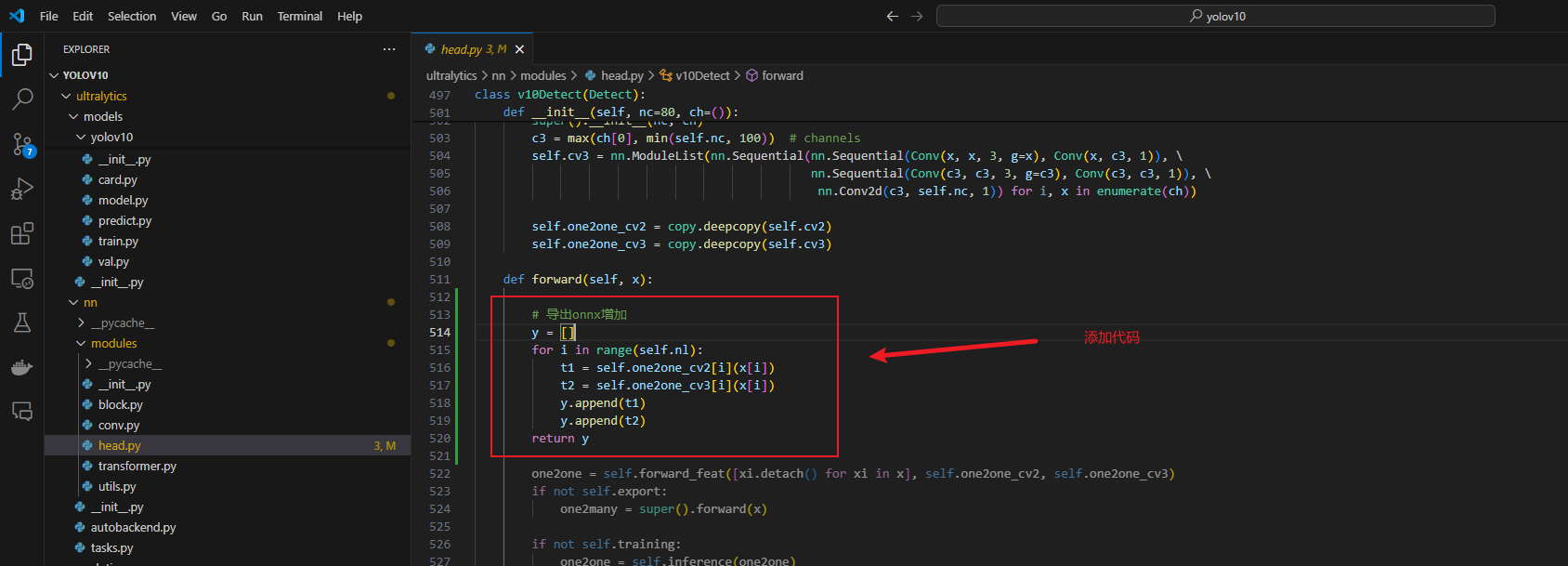
1 | # 导出onnx增加 |
编写一个python脚本test.py,模型、资源文件、GPU等信息改成自己的:
1 | from ultralytics import YOLOv10 |
运行脚本:
1 | python test.py |
输出会报错,但是不影响模型生成,会在yolov10\runs\detect\train\weights目录生成onnx模型文件
三、onnx转rknn
onnx转rknn需要用到rknn-toolkit2,这个工具暂时不支持windows,所以我们移步linux,我用的是虚拟机创建的ubuntu20.4的系统,建议使用conda管理环境,我这里使用conda安装了python3.8
rknn-toolkit2项目地址:https://github.com/airockchip/rknn-toolkit2/tree/master
将项目中http://rknn-toolkit2/rknn-toolkit2/packages/目录下的requirements_cp38-2.0.0b0.txt和rknn_toolkit2-2.0.0b0+9bab5682-cp38-cp38-linux_x86_64.whl下载下来,上传到虚拟机的一个目录下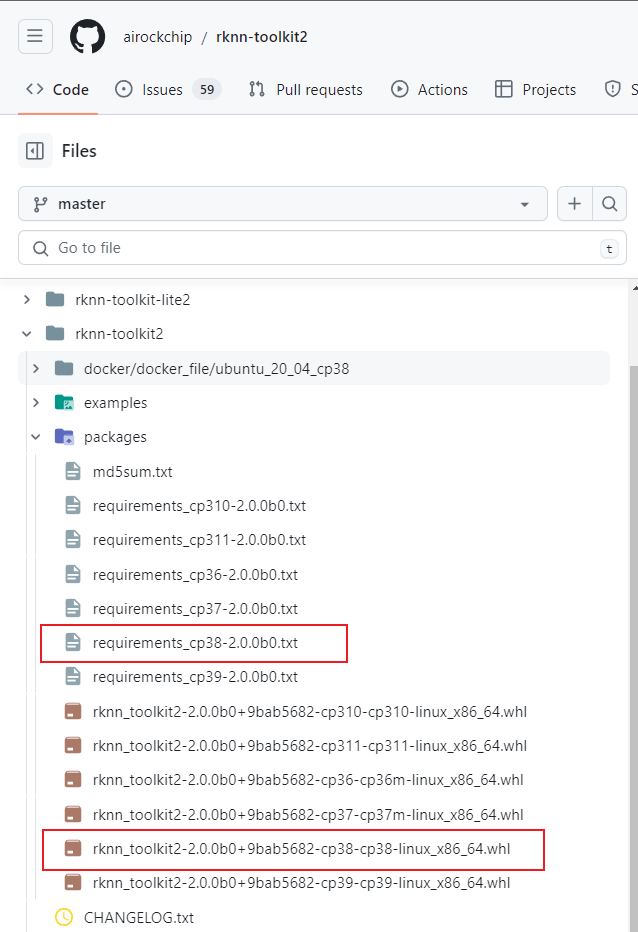
安装依赖:
1 | pip install -r requirements_cp38-2.0.0b0.txt |
安装rknn_toolkit2
1 | pip install rknn_toolkit2-2.0.0b0+9bab5682-cp38-cp38-linux_x86_64.whl |
下载一位大佬提供写好的代码进行转化:
项目地址:https://github.com/cqu20160901/yolov10_onnx_rknn_horizon_tensorRT/tree/main
按下图所示,将onnx模型换成自己的,将onnx2rknn_demo_ZQ.py文件中的标签集和模型尺寸修改为自己的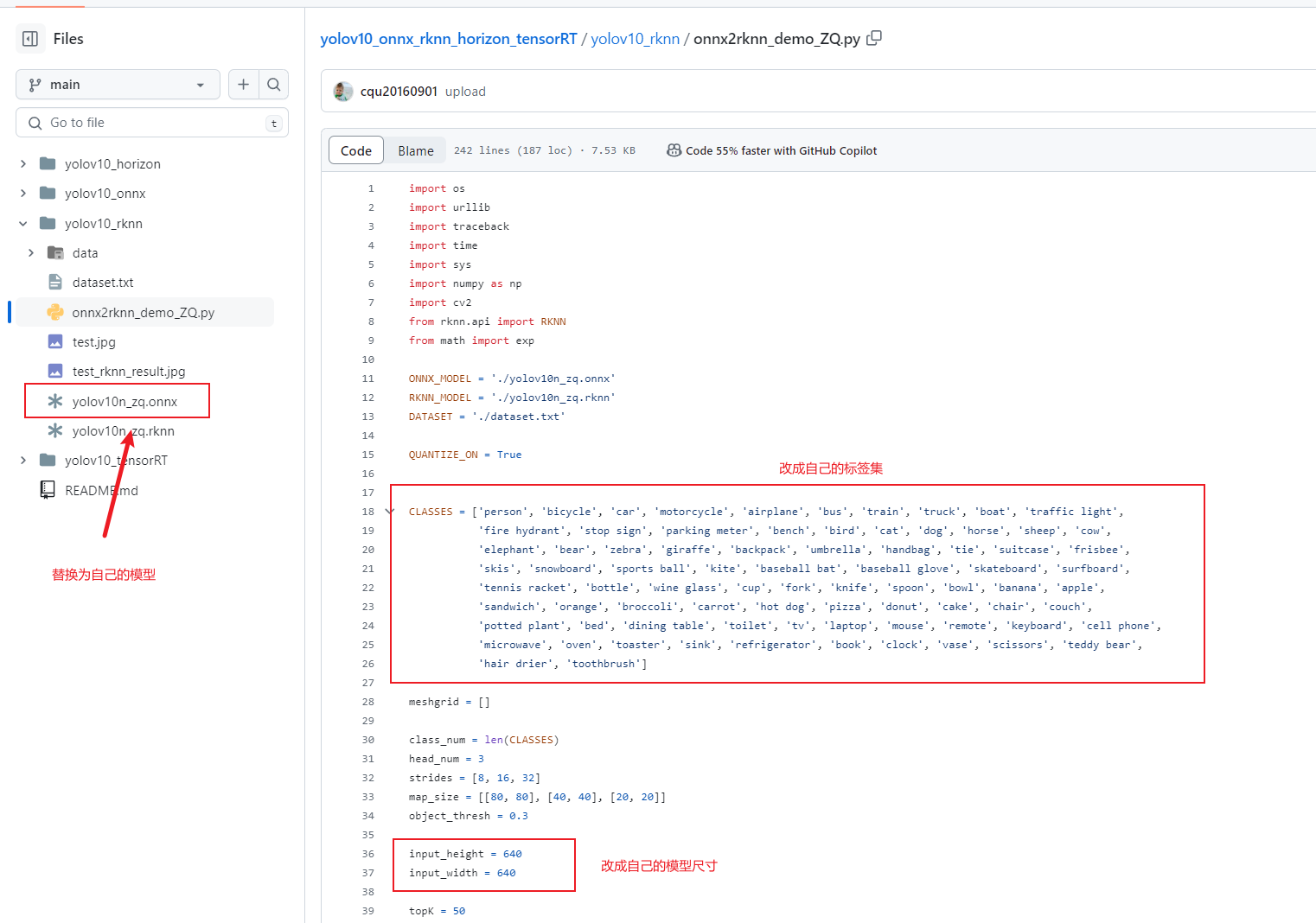
运行脚本就会生成rknn模型
1 | python onnx2rknn_demo_ZQ.py |
四、在rk3588S上使用rknn进行目标检测
将自己的rknn模型上传到板子上,再在板子上安装rknn-toolkit-lite2,将上面的requirements_cp38-2.0.0b0.txt和同一个项目下的rknn_toolkit_lite2-2.0.0b0-cp38-cp38-linux_aarch64.whl下载下来上传到板子的某个目录下
安装依赖:
1 | pip install -r requirements_cp38-2.0.0b0.txt |
安装rknn-toolkit-lite2
1 | pip install rknn_toolkit_lite2-2.0.0b0-cp38-cp38-linux_aarch64.whl |
下载同样由上面那位大佬提供的示例代码:https://github.com/cqu20160901/yolov10_rknn_Cplusplus
将main文件下的模型路径和检测图片等路径修改成自己的
将include/postprocess.h文件中的标签类目数量ClassNum修改为自己的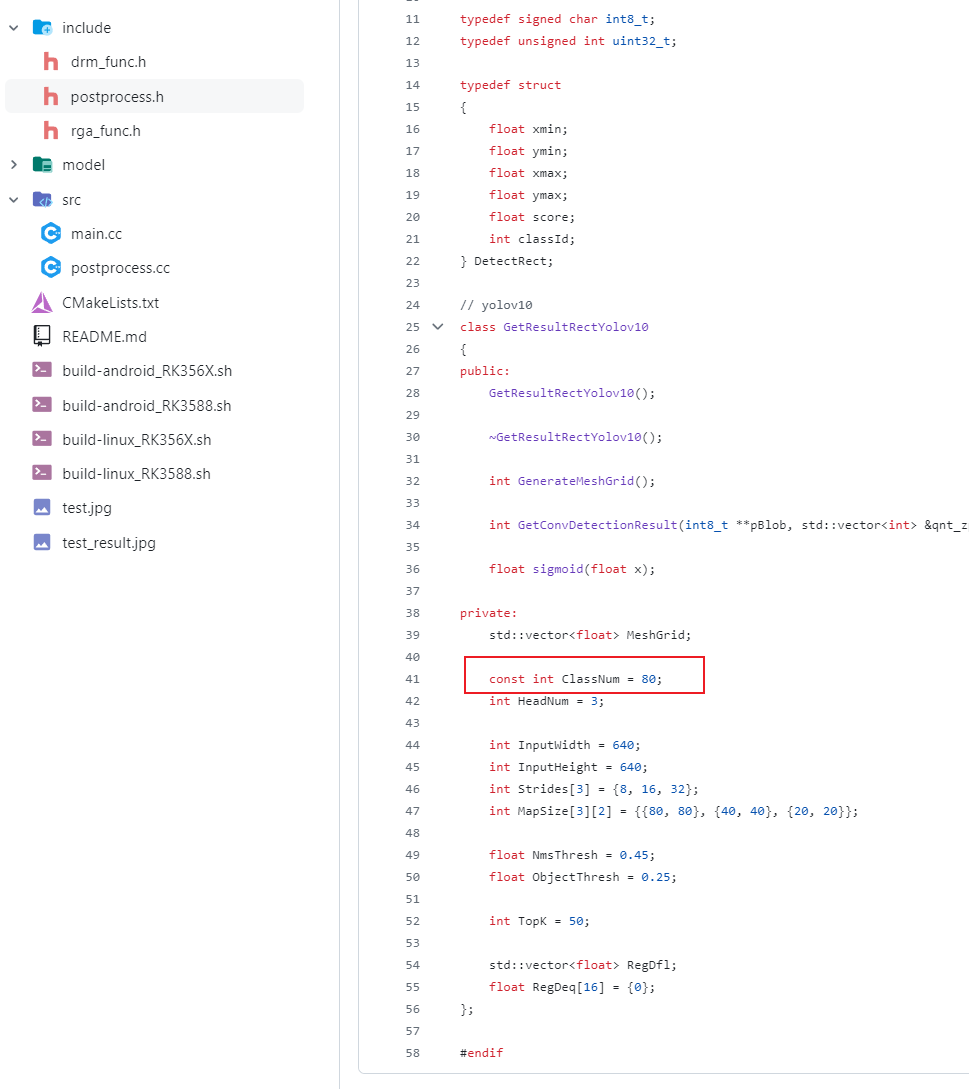
编译
1 | bash build-linux_RK3588.sh |
运行
1 | cd install/rknn_yolov10_demo_open |

至此完成了识别过程,我这里对标签进行了翻译,如果没有做调整这里不是zt30,而是数字,另外如果你发现你识别出来的精度和pt模型的精度不一致,应该是检测图像尺寸问题,这个有很多种办法处理,这里不再赘述。
参考资料:
https://github.com/THU-MIG/yolov10
https://github.com/airockchip/rknn-toolkit2
https://github.com/cqu20160901/yolov10_onnx_rknn_horizon_tensorRT
https://github.com/cqu20160901/yolov10_rknn_Cplusplus